Pràctiques
IMPORTANT
Aquestes pràctiques no són obligatòries, però sí recomanables per a poder realitzar els entregables (Aules).
Per començar a fer aquestes pràctiques, es imprescindible haver completat les de la unitat 5.
Pràctica 1 - Anàlisis de riscos d'una arquitectura
Com a cas base que s'utilitzara durant tota la unitat es planteja el següent:
Una web educativa que:
- Té pics de trànsit en moments concrets.
- No es pot permetre caigudes.
- Ha de poder diagnosticar errors.
Per a dissenyar-la, dues empreses han presentat les següents propostes: Empresa 1:
- 1 VPC
- 1 subnet pública
- 1 EC2
- Internet Gateway
- Usuari accedint directament a la EC2
Empresa 2:
- 1 VPC
- 2 subnets públiques (AZ diferents)
- 2 EC2 (una per subnet)
- Sense balancejador (expressament)
La teua tasca com a expert és, per a cada diagrama:
- Llistar els SPOF.
- Indicar almenys 2 fallades reals possibles.
- Relacionar cada problema amb un pilar.
- Proposar una millora concreta (sense entrar encara en serveis concrets).
Pràctica 2 - Implementació d'un Application Load Balancer (ALB)
En aquesta pràctica desplegarem una arquitectura real amb un Load Balancer i demostrarem la seua la tolerància a fallades.
Per fer-ho, dissenyarem la següent estructura:
- 1 VPC (podem gastar la que ja tenim o fer una nova)
- 2 subnets públiques en AZ diferents
- 2 EC2 (una per subnet)
- 1 Load Balancer (des de EC2)
- 1 Target Group
- Security Groups correctament configurats per permetre port 22 i 80
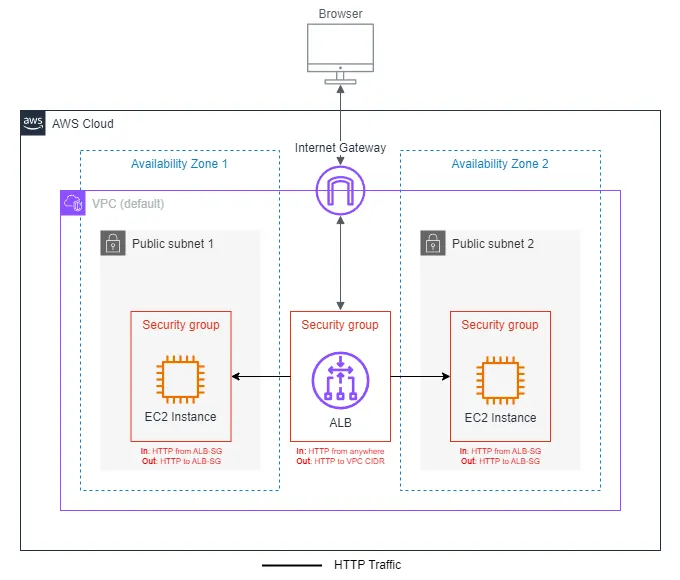
Com pots observar, el tràfic no va directe a les EC2 sino que passa pel ALB i aquest és el que distribueix el tràfic. Per fer-ho, cal que els grups de seguretat tinguen els permisos adequats per permetre-ho.
1. Creació dels grups de seguretat
Primer crearem els dos grups de seguretat que controlaran la entrada i eixida de tràfic, un per a l'ALB i altre per a les EC".
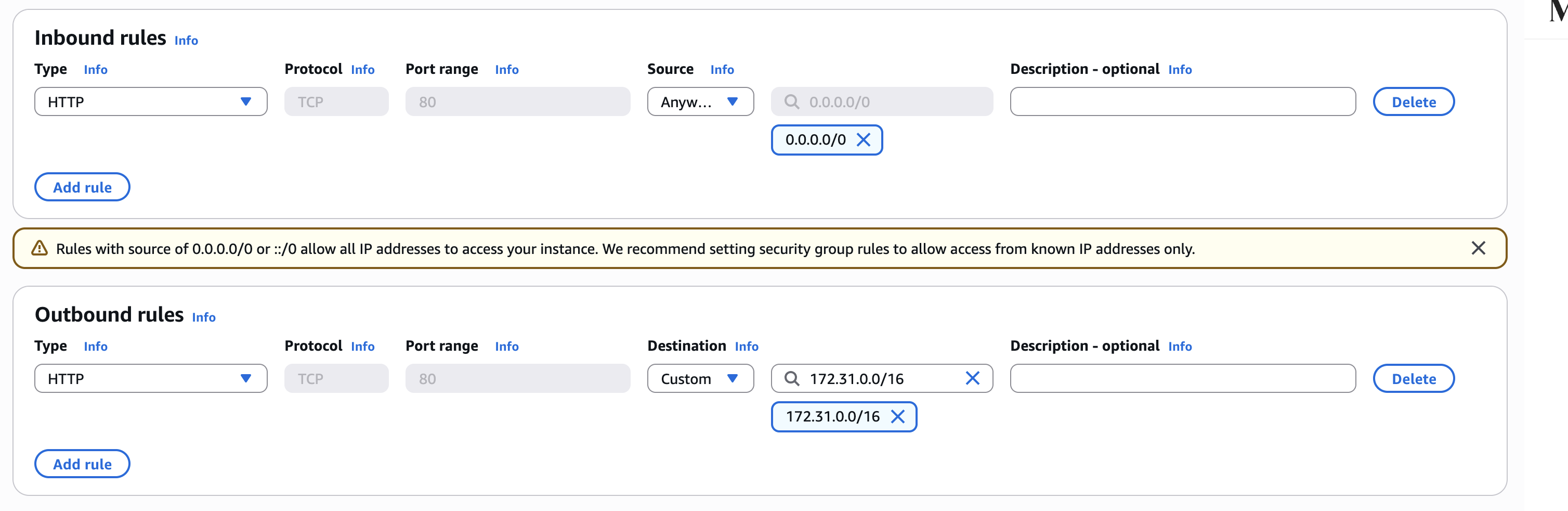
D'una banda crearem un grup de seguretat per a l'ALB que permeta entrada HTTP a HTTP i eixida HTTP cap a la nostra VPC.
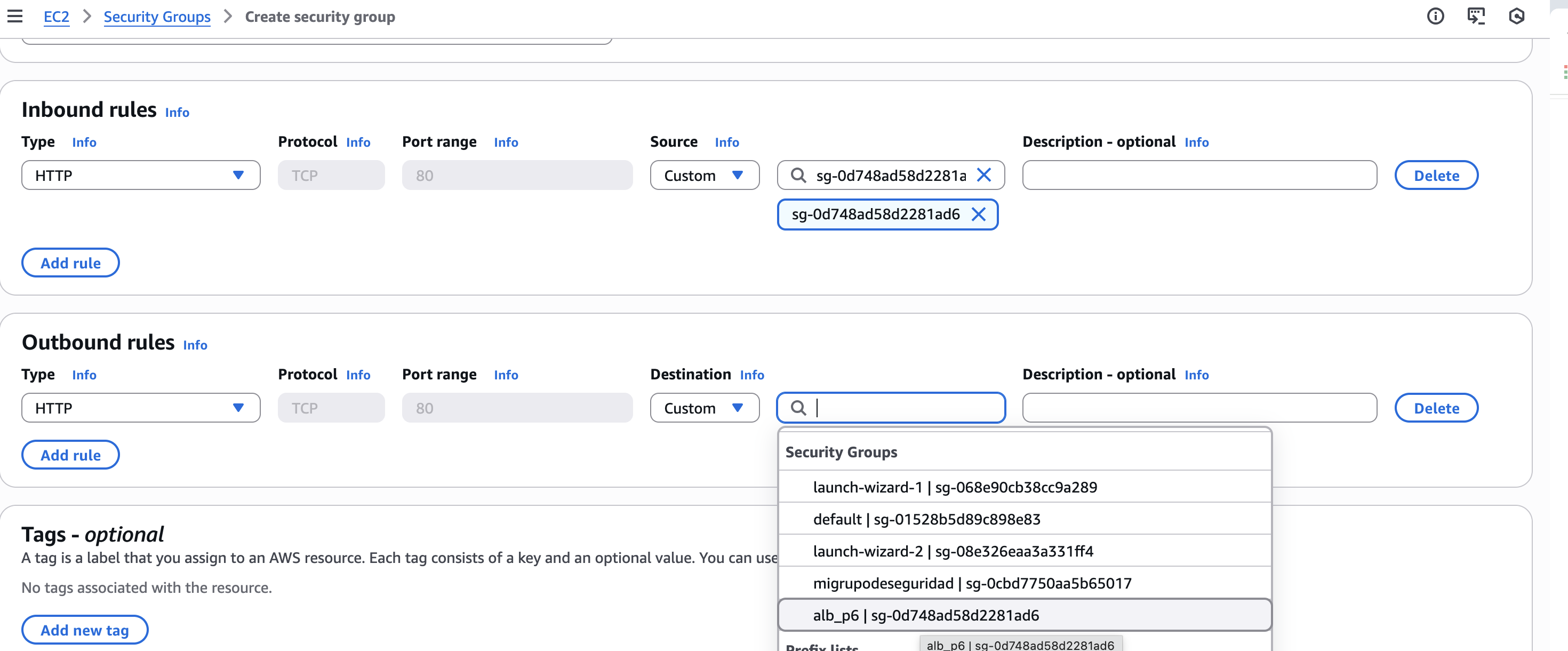
D'altra banda, crearem un grup de seguretat que aprofitarem a les dos EC2 i que, molt important, permeta el tràfic d'entrada i d'eixida cap al grup de seguretat que hem creat en el pas anterior, es a dir, el grup de seguretat de l'ALB.
Entorn de proves
La configuració mostrada més amunt és per a un entorn de producció. Per a aquesta pràctica i la relització de proves, afegirem a més com a regla Outbound que permeta tot el tràfic TCP a tots. A més, si volem connectar-se per SSH, també caldrà afegir-lo com a regla inbound.
2. Creació d'una instància EC2 en cada AZ
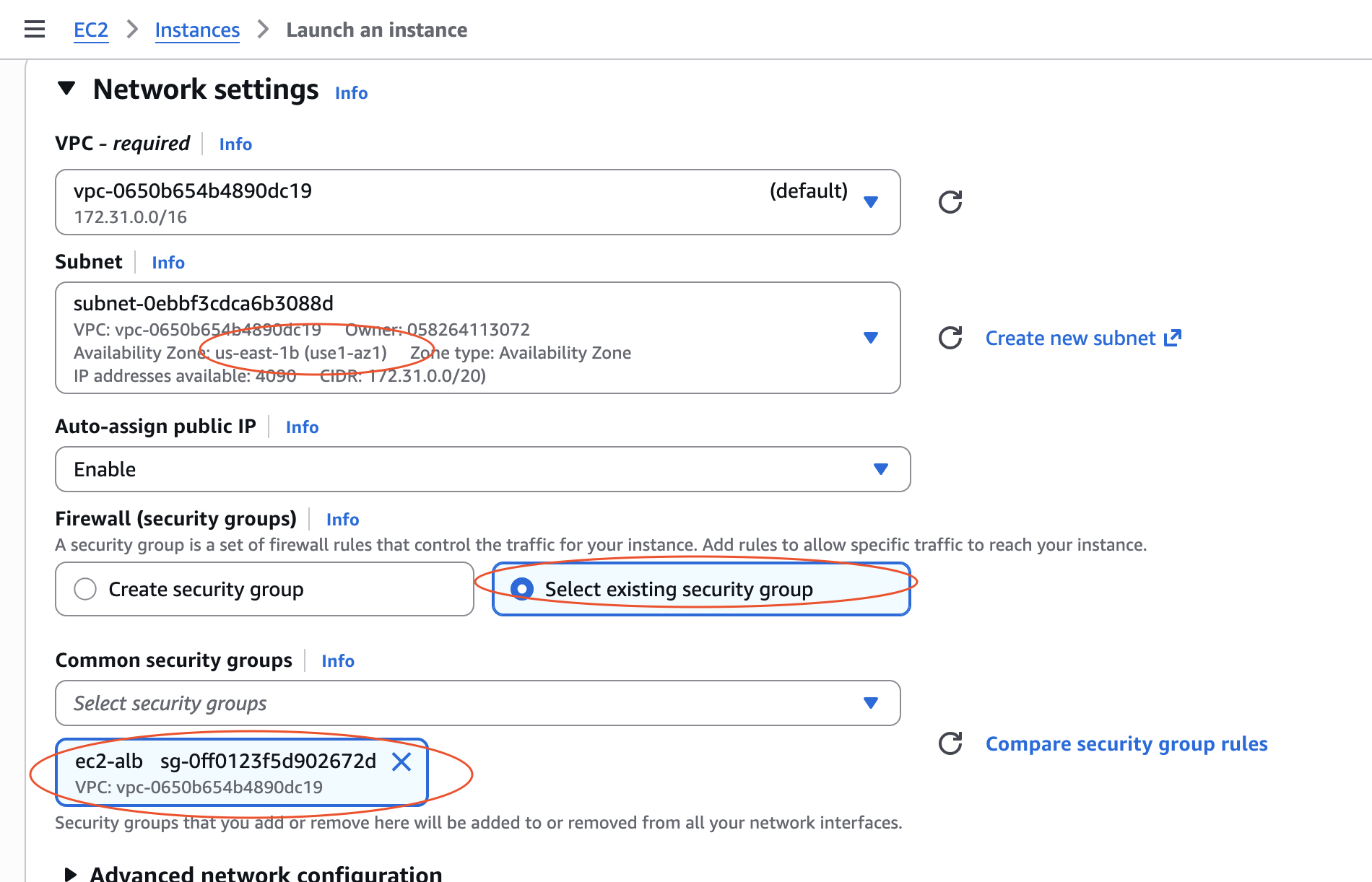
- Crearem la primera instància a una zona de disponibilitat. Fàrem una ubuntu amb tot per defecte i cal tenir en compte que caldrà crear una subxarxa per a cada EC2 (en el cas que estigues reutilitzant la VPC per defecte, no cal crear una nova, simplement cal seleccionar alguna de les ja creades) i seleccionar una zona de disponibilitat diferent per a cada instància. També cal seleccionar el SG que hem creat per a les EC2.
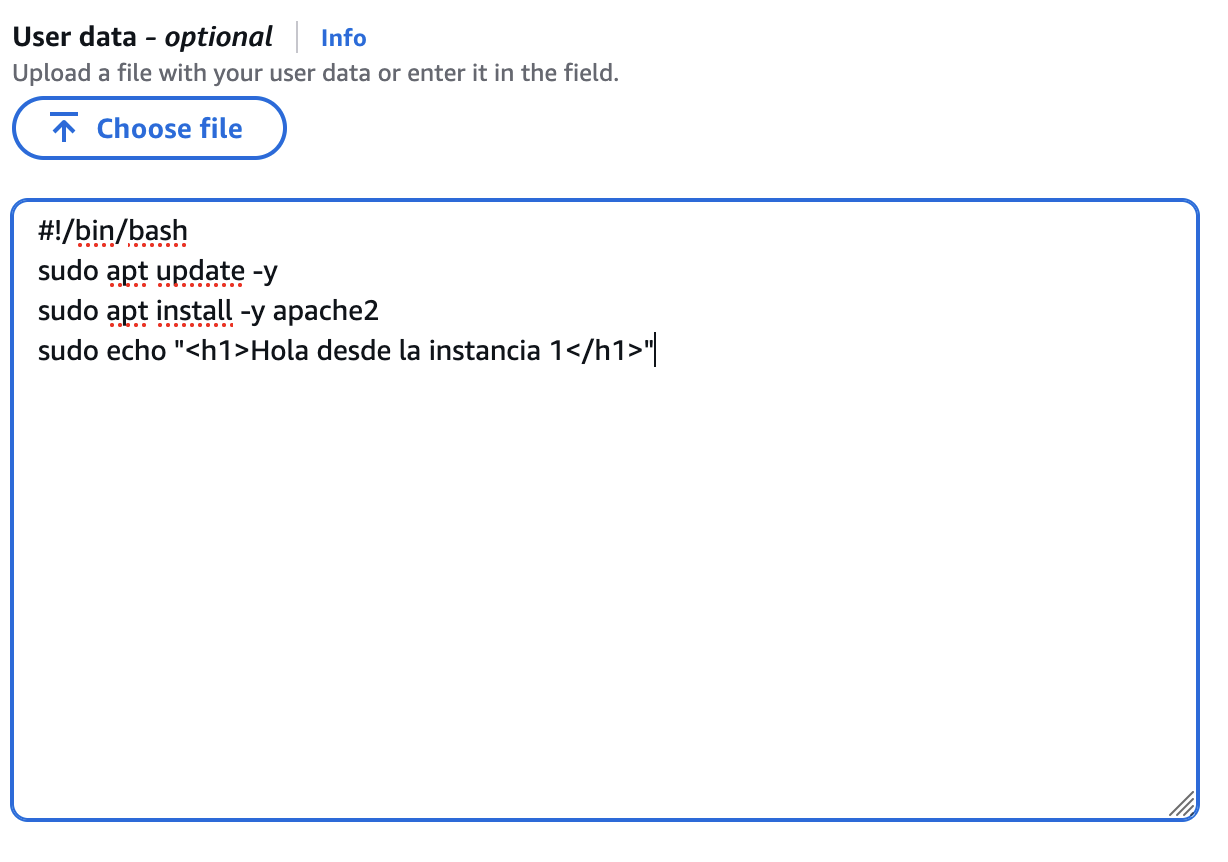
- Per últim, ens connectarem per ssh i instal·larem un servidor web. Per a veure com funciona el balancejador web de forma més clara, indicarem un missatge diferent a cadascuna de les EC2 modificant el fitxer index.html. Per exemple, jo ho he canviat per Hola des de la primera instància
Atenció a l'script de dalt
Cal cambiar el missatge de la web en cada instància per poder diferenciar quan el balancejador ens està enviant a un lloc o altre.
Aquest procés es repetirà per a les dues EC2 assegurant-se que estan en AZ diferents.
3. Creació del balancejador de càrrega (ALB)
- Des d'EC2, accedim a la secció Load Balancers i fem click en Create Load Balancer
- Seleccionem Application Load Balancer i li donel a crear.
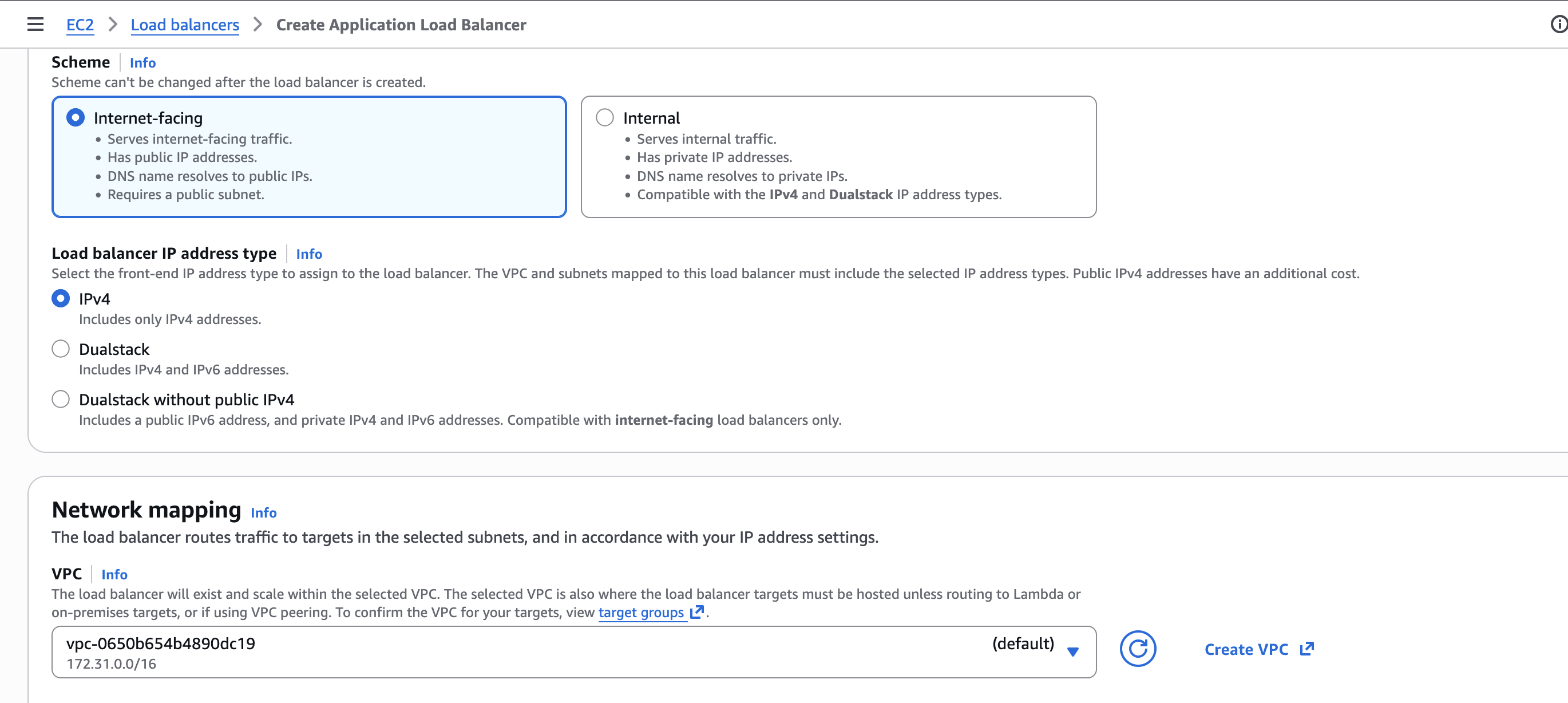
- Li posem nom, i ens assegurem que està seleccionat Internet-facing, IPv4 i la VPC que estem utilitzant
- Seleccionem les dues AZ on hem posat les EC2. Si no ho recordeu, podeu anar a les instàncies i revisar-ho.

- Seleccionem el grup de seguretat que havíem creat per a l'ALB abans.
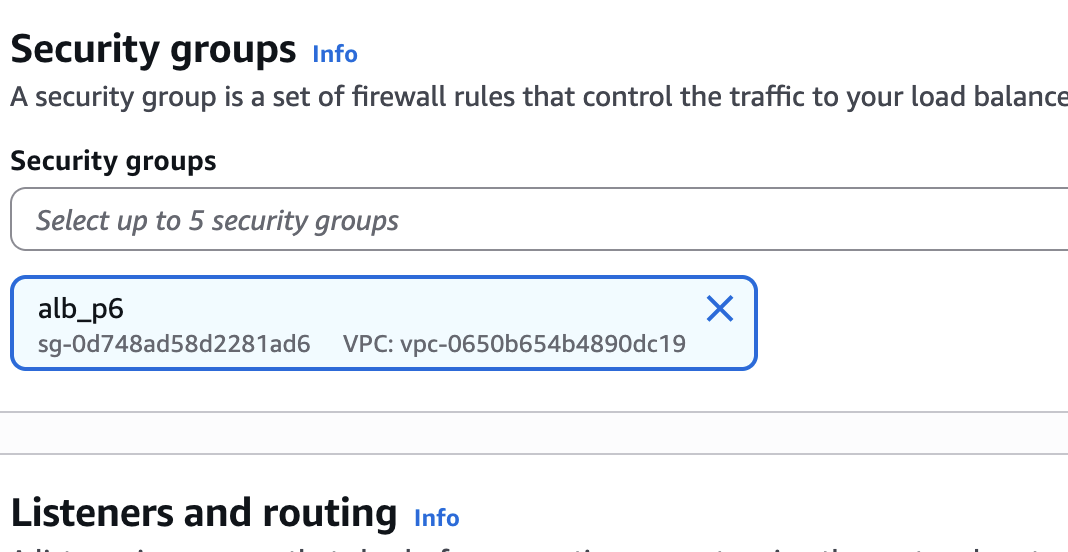
4. Creació del Target Group
- Continuant en la mateixa finestra, apleguem a la secció Listeners and routing on li donarem a Create target group. En aquesta part és on li diguem al nostre balancejador de càrrega a qui ha de balancejar.
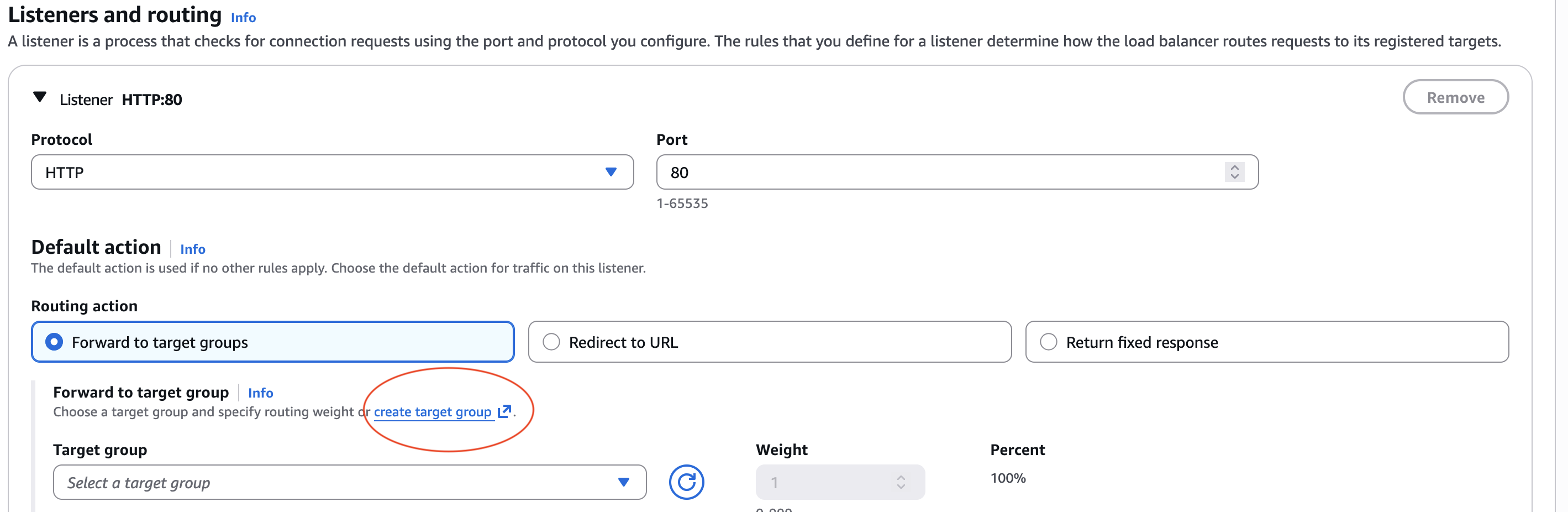
- En el primer pas, sols afegirem el nom que li posem al Target group, la resta ho deixarem per defecte i donarem a next.
- En el següent pas deguem vore totes les instàncies que tenim creades en la VPC seleccionada en el pas anterior. Selecciona les que són d'interés per a la pràctica i inclou-les donant-li al botó Include as pending below
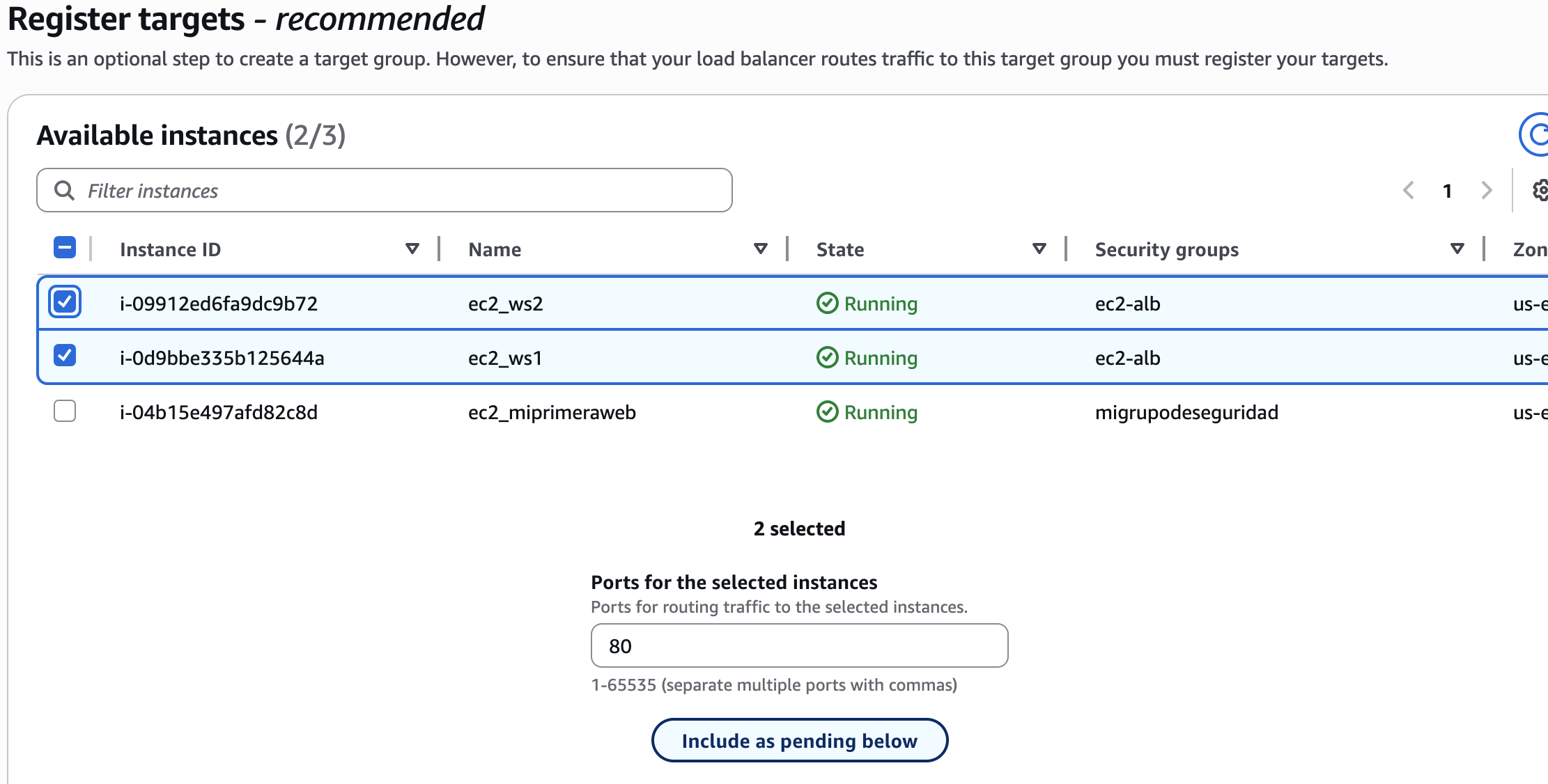
- Veurem que han passat a estar en la secció Review Target i donarem a next i finalitzarem el procés.
- Una vegada el TG està creat, tornarem a la finestra on estabem creant el nostre ALB (recordeu que se'ns havia obert una nova i no havíem tancat l'anterior) i després de actualitzar la secció de Target groups veurem com ja apareix el que acabem de crear.
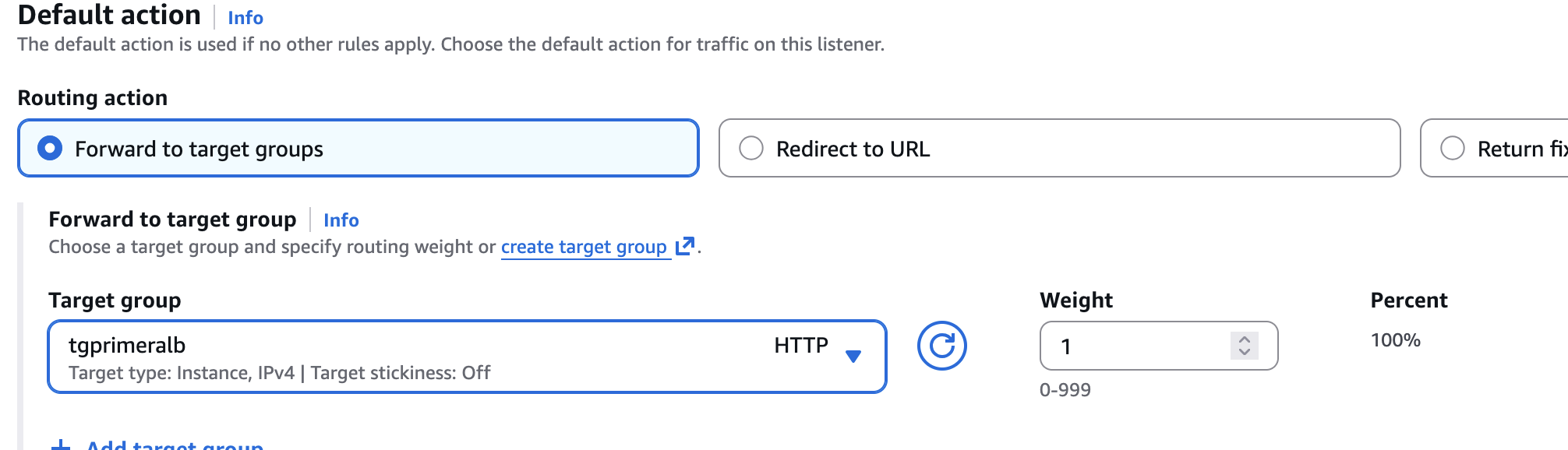
- I ja podem donarli a crear el Load Balancer i després de dos minuts, utilitzant el DNS name que apareix al Load balancer podem accedir a través del navegador a les EC2.
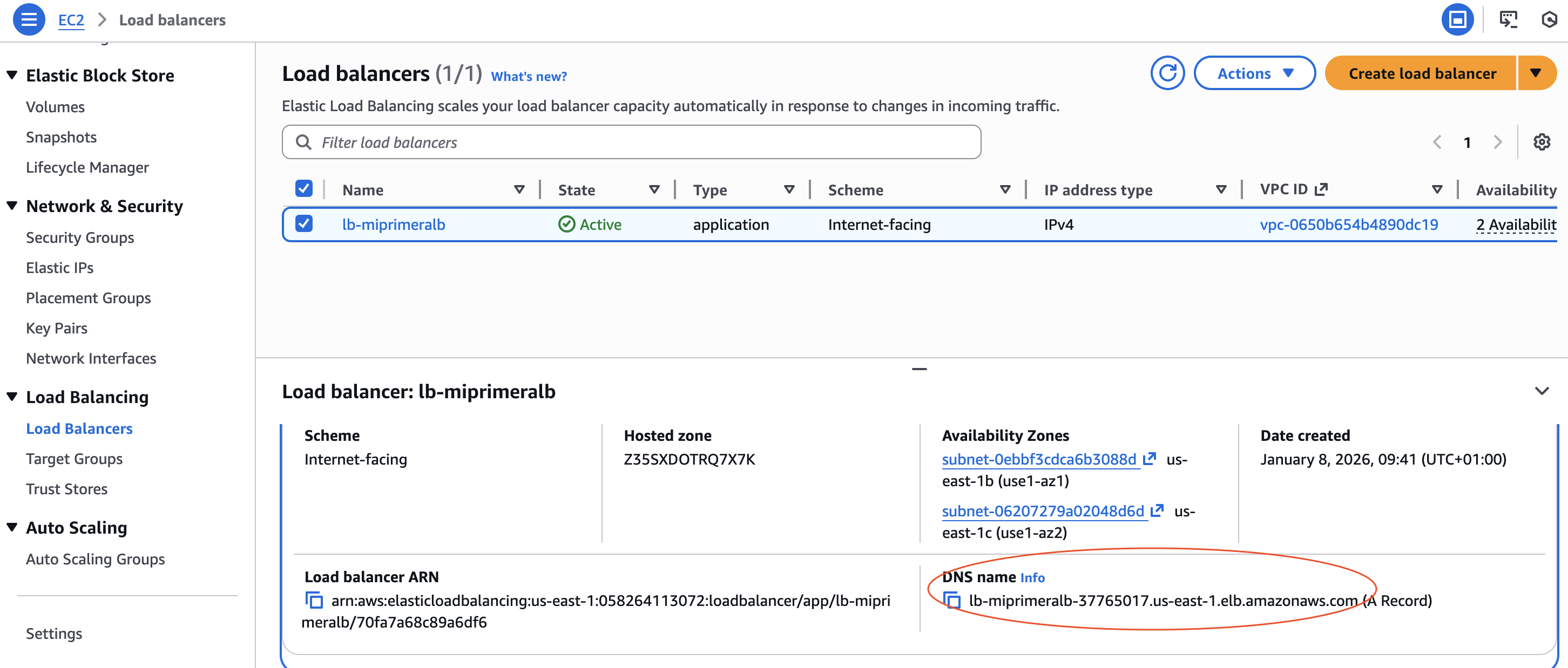
5. Comprobació de la pràctica
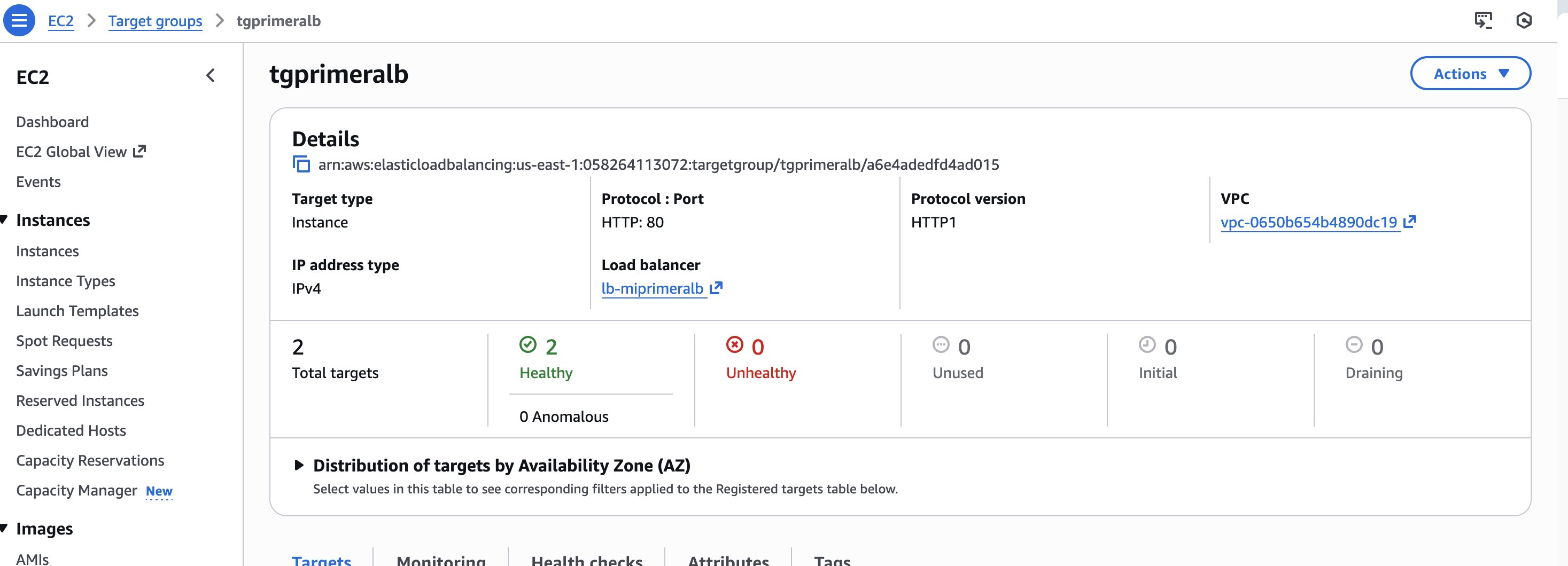
- Si recarreguem, veurem com cada vegada ens envia a un servidor diferent, es a dir, balanceja la càrrega de forma exitosa.


- A més, si accedim al Target group veurem com els Healh checks estan en verd, es a dir, ha pogut connectar-se amb èxit a les dues instàncies que té assignades i comprobar que estan up & running sense cap problema.
Pràctica 3 - Monitorització amb CloudWatch
La pràctica es realitza sobre la mateixa arquitectura del bloc anterior: dues instàncies EC2 darrere d’un Load Balancer, distribuïdes en diferents Availability Zones. És important remarcar que el sistema ja funciona abans de començar aquesta pràctica. CloudWatch no serveix per a fer que el sistema funcione, sinó per a entendre com està funcionant.
Context inicial de la pràctica
Ens situem en un escenari molt realista: una aplicació web educativa que funciona correctament la major part del temps, però que pot patir situacions de càrrega elevada en moments puntuals (exàmens, lliuraments, consultes massives). El sistema no cau gràcies al Load Balancer, però això no significa que no hi haja riscos.
La pregunta és la següent: Com podem saber que el sistema està començant a patir abans que deixe de funcionar?
Observació de mètriques d'una EC2
El primer pas és aprendre a mirar dades reals del sistema. Abans de crear alarmes o dashboards, és fonamental saber quines mètriques existixen i què signifiquen.
Per fer-ho, podem accedir directament a través del menú EC2 a la pestanya de monitorització:
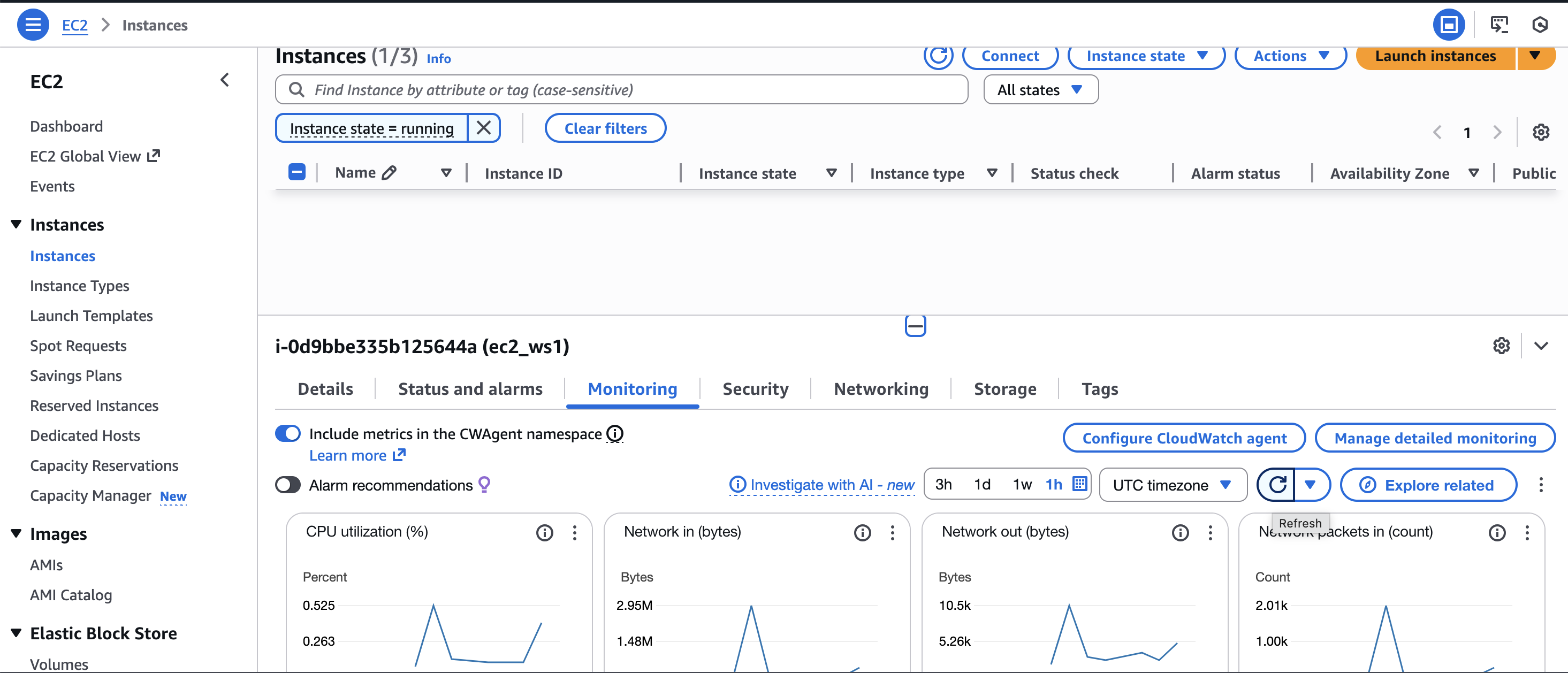
Allí es poden veure gràfics com l’ús de CPU, el trànsit de xarxa o l’estat general de la instància.
Cal tenir en compte que una mètrica és només informació. Veure que la CPU puja no és encara un problema; el problema apareix quan aquesta situació es manté en el temps.
Creació d'una alarma
Una vegada entés que és una mètrica, el següent pas és transformar aquesta informació en un avís. Ací és on entren en joc les alarmes de CloudWatch.
La pràctica consistix a crear una alarma associada a la CPU d’una única instància EC2.
Des de la consola d’AWS, accedix al servei CloudWatch i entra a l’apartat d’alarmes. Allí li donarem a al botó per a crear l'alarma.
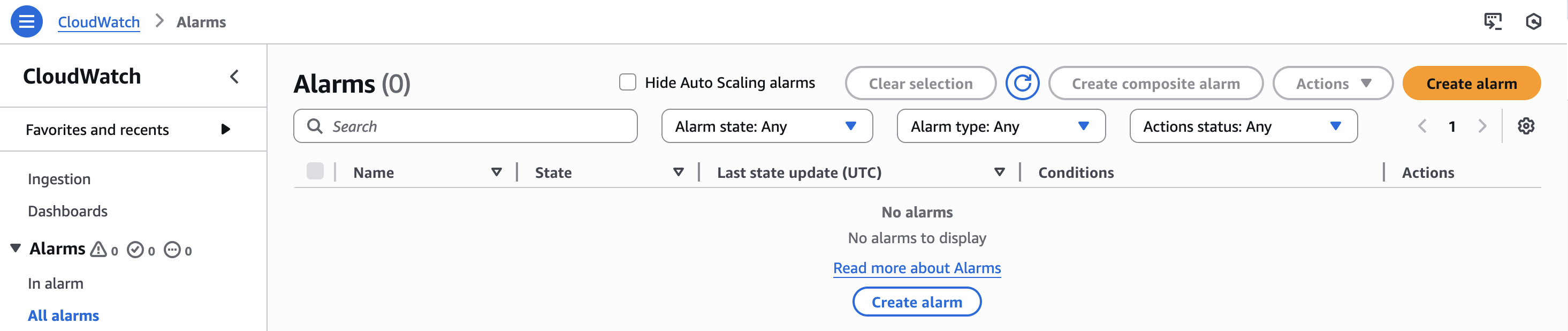
Recorda
Una alarma sempre es basa en una mètrica, mai en una intuïció
Selecció de la mètrica
En iniciar la creació de l’alarma, el primer pas és seleccionar la mètrica que es vol monitoritzar. En aquest cas, es treballa amb una mètrica d’EC2, concretament l’ús de CPU d’una instància concreta.
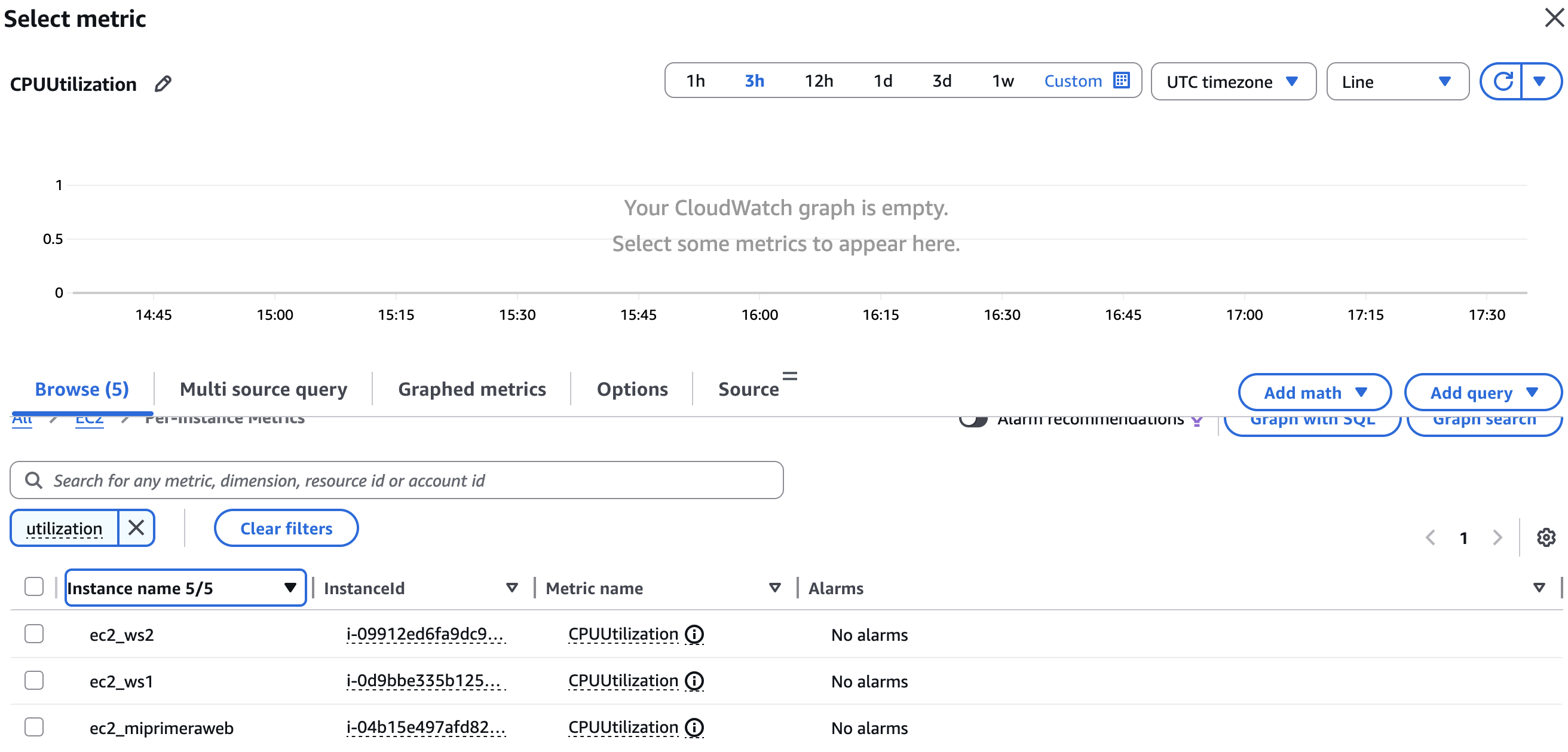
Informació
Si sabem quina mètrica busquem, podem escriure-ho al quadre de búsqueda. En altre cas, podem buscar-la mitjançánt les categories que apareixen. Recorda que la mètrica es per instància.
Definició de la condició
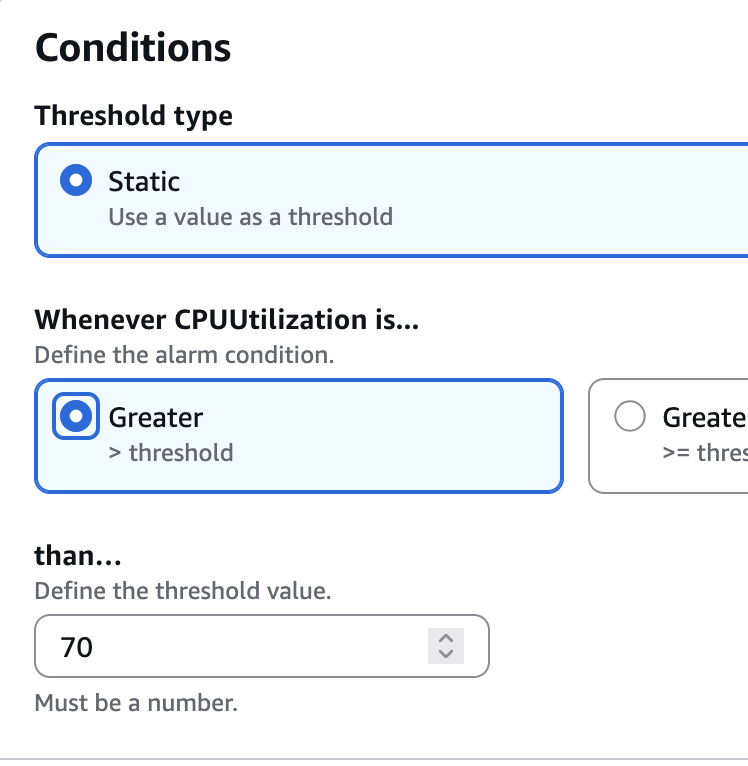
Una vegada seleccionada la mètrica, es definix la condició que farà saltar l’alarma. En aquesta pràctica es treballa amb una mitjana de CPU durant 5 minuts (Average) i amb un llímit raonable (per exemple, per damunt del 70 %).

Informació
Cal definir bé l'alarma per a no tindre alarmes nervioses. Si una alarma salta per qualsevol pic puntual, deixa de ser útil. El que busquem és detectar situacions sostingudes que indiquen un risc real, per això gastem la mitjana en 5 minuts.
Accions de l’alarma
En principi, en AWS Academy no es poden configurar notificacions externes, però és important entendre que, en un entorn real, aquest seria el moment en què s’enviarien correus o avisos a un equip tècnic. En aquesta pràctica, l’objectiu és simplement observar el canvi d’estat de l’alarma.
A més des d'ací es poden configurar accions que s'executaran una vegada es llance l'alarma, com per exemple, parar una instancia EC2.
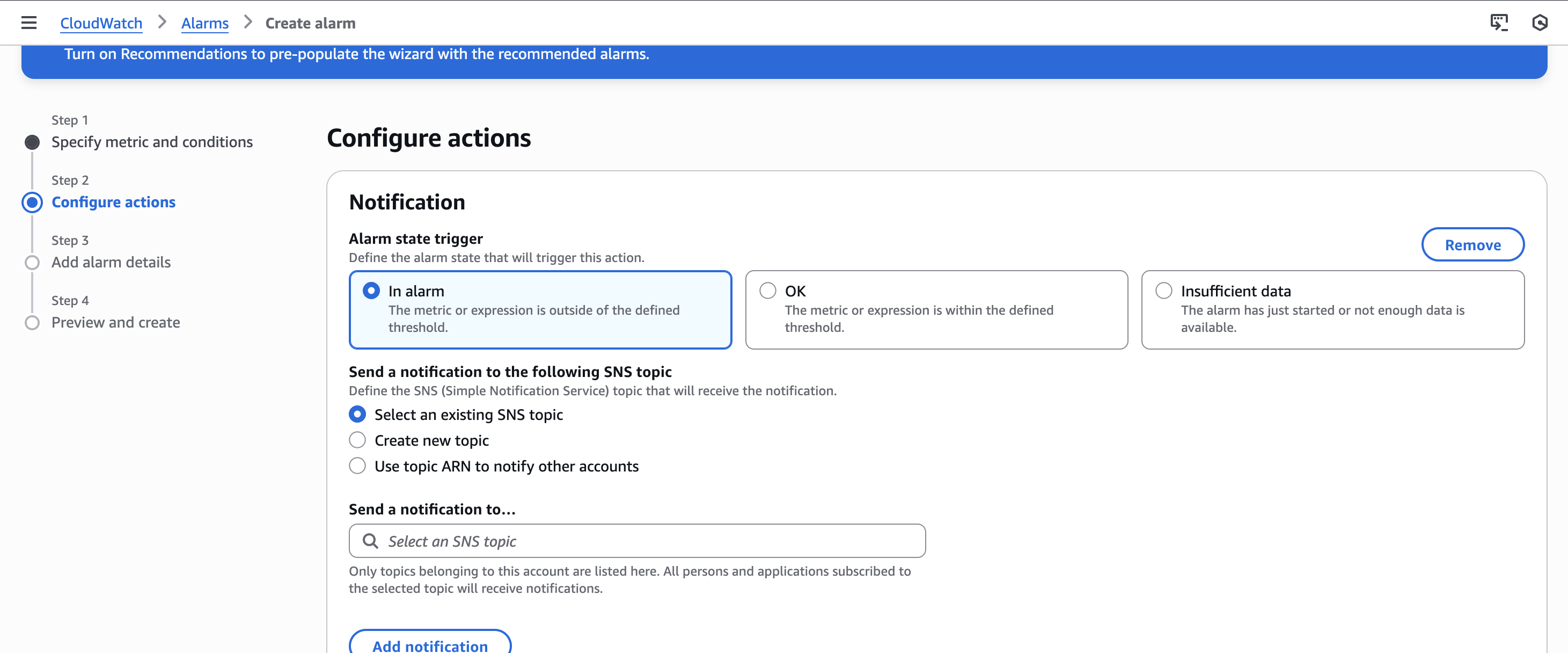
Per continuar, cal crear un new topic i introduïr el correu electrònic que rebria la notificació.
Creació i revisió de l’alarma
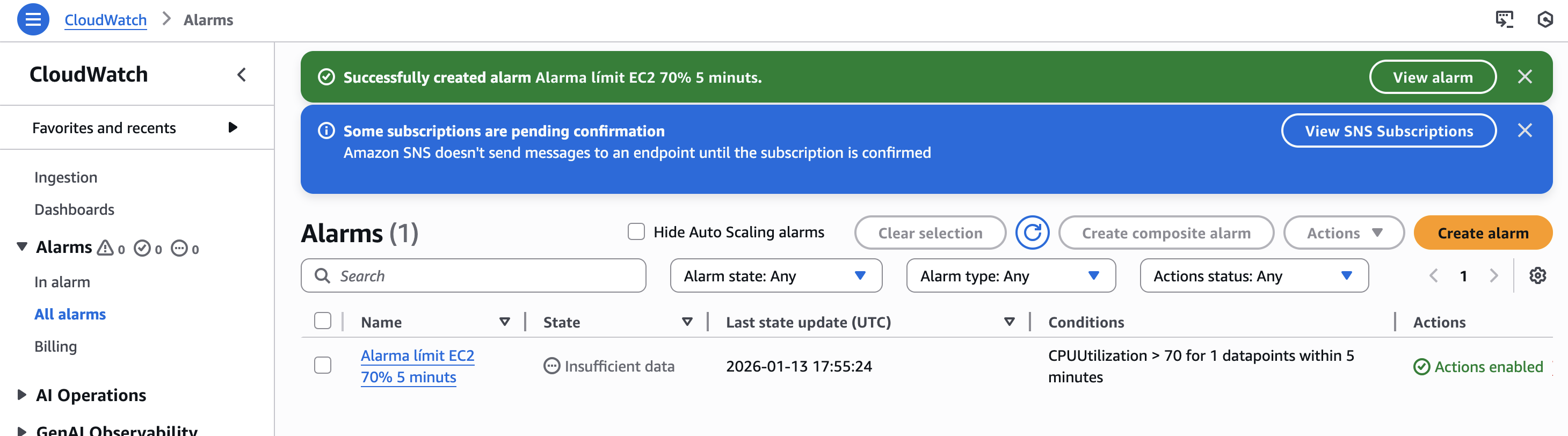
Finalment, es dona un nom clar i descriptiu a l’alarma i es crea. Una vegada creada, es pot veure que l’alarma apareix inicialment en estat OK, indicant que el sistema funciona dins dels paràmetres esperats.
Construcció d’un dashboard de CloudWatch
Amb l’alarma creada, el següent pas és construir una visió global del sistema mitjançant un dashboard.
Des de CloudWatch, accedix a l’apartat de dashboards i crea un nou dashboard amb un nom identificatiu. Aquest dashboard serà el lloc on s’agruparà la informació més rellevant del sistema.
Afegir mètriques al dashboard
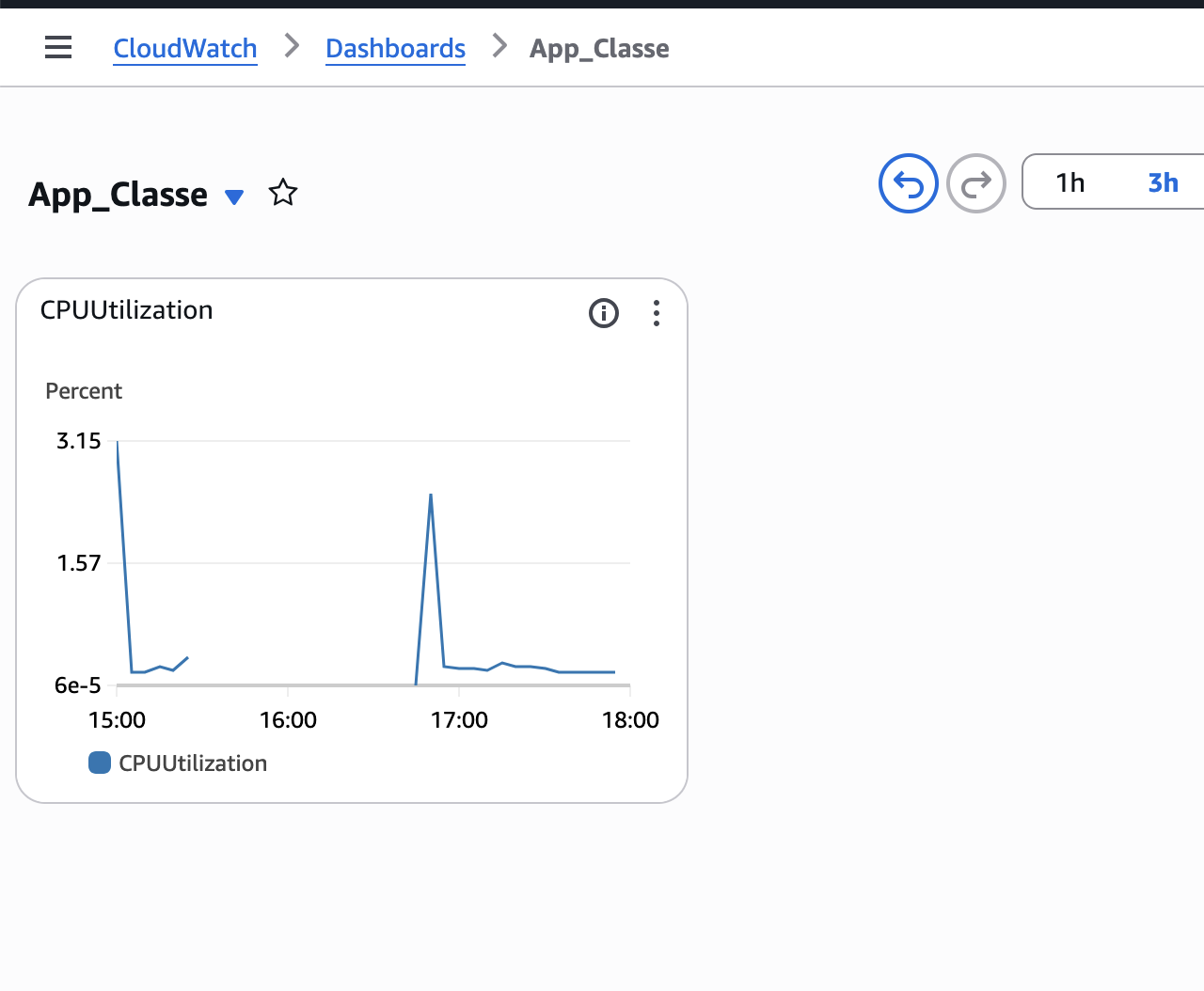
El primer element que afegirem al dashboard és un gràfic de línies que mostre la càrrega d’una instància EC2, normalment la CPU. Aquest gràfic permet veure visualment com evoluciona la càrrega al llarg del temps. Per fer-ho, seleccionarem un widget de tipus Metrics-Line i buscarem la mètrica adequada.
A continuació, afegirem una mètrica relacionada amb el Load Balancer, com ara el nombre de peticions o l’estat de salut dels targets. Açò permet entendre no només com estan les instàncies, sinó també com està sent utilitzat el sistema. Aquestes també són de tipus Line o Number. Pots provar i veuràs la diferència.
Finalment, afegirem un indicador senzill que mostre si hi ha instàncies fora de servei. Aquest element és clau perquè, d’un colp d’ull, es puga detectar si el sistema ha patit alguna incidència.
Investiga i prova
Prova tu mateix a fer altres dashboards i examina totes les possibles mètriques que es poden utilitzar dins d'aquestos.
També es poden afegir seguiment a les alarmes als nostres dashboards i el nombre de mètriques disponibles va en augment.