U6 — Arquitectura escalable, resilient i monitorització
🎯 RA's vinculats: RA1, RA2, RA3 i RA4
Concepte previ: Single Point of failure (SPOF)
Un SPOF és qualsevol component que, si falla, fa caure tot el sistema.
Exemples molt habituals:
- Una única instància EC2 que dona tot el servei web.
- Tota l’arquitectura dins d’una sola AZ (Availability Zone). (Alta disponibilitat sempre va lligat a tindre com a mínim dos AZ)
Conseqüències:
- Caiguda total davant una fallada d’instància, manteniment, error humà o saturació.
- Recuperació lenta (depens de reiniciar o recrear eixa mateixa peça).
Què és alta disponibilitat (HA) i què NO és
Alta disponibilitat significa: - El servei continua disponible encara que falle una part del sistema.
NO significa:
- Tindre còpies de seguretat (els backups ajuden a recuperar, no a evitar la caiguda).
- Tindre un servidor molt potent (això és escalat vertical).
Exemple clar
- HA: s’apaga una EC2 i la web continua funcionant perquè una altra respon.
- Backup: la web cau i després es restaura.
Els 3 pilars del Well architected
1. Reliability (Fiabilitat) — “Què passa si falla alguna cosa?”
Preguntes clau:
- Hi ha algun SPOF?
- Hi ha redundància (més d’una instància o AZ)?
- Hi ha mecanismes automàtics per deixar d’usar el que falla?
Exemple real
Una EC2 deixa de respondre → sense redundància, servei caigut.
2. Operational Excellence (Excel·lència operacional) — “Me n’assabente i puc reaccionar?”
Preguntes clau:
- Tinc mètriques per saber que alguna cosa va mal?
- Tinc logs per diagnosticar?
- Puc saber qui ha canviat què?
Exemple real
“La web va lenta” → sense mètriques, només hi ha suposicions.
3. Performance Efficiency (Eficiència del rendiment) — “Aguanta pics de càrrega?”
Preguntes clau:
- Es pot repartir la càrrega?
- Es pot escalar horitzontalment (més instàncies)?
- Hi ha colls de botella evidents?
Exemple real
En una web de venta d'entrades, està previst que isquen avui les d'un festival a preu reduït → molts usuaris alhora.
Pràctica
En aquest punt dels continguts, es recomana fer la pràctica 1.
Balanceig de càrrega i alta disponibilitat (Multi-AZ)
Un escenari molt habitual a DevOps és el següent:
- Una web funciona correctament amb una EC2.
- Arriba un pic de trànsit
- La instància satura CPU o deixa de respondre.
Conseqüències:
- Lentitud general.
- Caiguda del servei.
- L’usuari veu errors.
- L’administrador no té marge de reacció ràpida.
Què és el balanceig de càrrega?
El balanceig de càrrega consistix a:
- Tindre un punt d’entrada únic al sistema.
- Repartir les peticions entrants entre diverses instàncies.
- Evitar que una sola màquina suporte tot el treball.
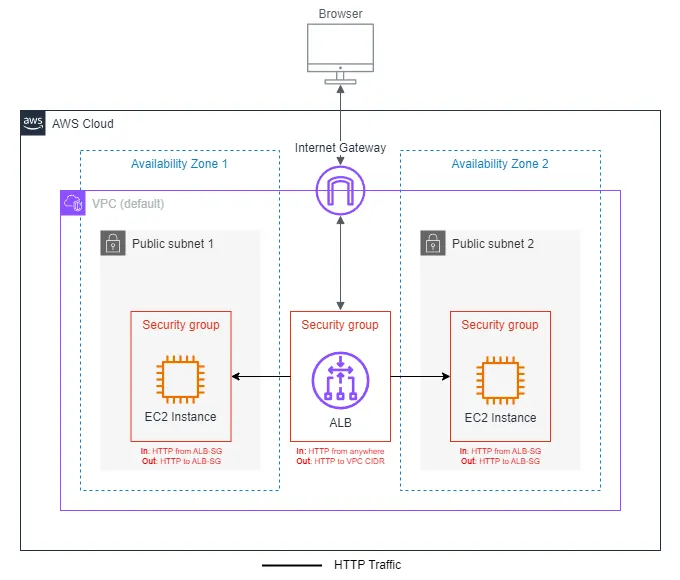
L’element que fa esta funció és el Load Balancer.
Es a dir:
- L’usuari no accedix mai directament a les EC2.
- L’usuari sempre accedix al Load Balancer.
- El Load Balancer decidix a quina instància enviar cada petició.
En AWS, el servei que realitza aquesta funciçó s'anomena Elastic Load Balancer i ara per ara es troba com a apartat dins de la secció EC2.
Aquest servei:
- Dissenyat per a HTTP/HTTPS.
- Treballa amb rutes i ports.
- Usa Target Groups. (S'estudia a continuació)
- Fa health checks automàtics. (S'estudia a continuació)
Què és un Target group?
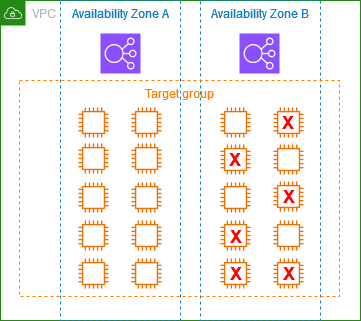
Un Target Group és:
- El conjunt d’EC2 que poden rebre trànsit.
- El lloc on el Load Balancer comprova l’estat de cada instància.
Estats possibles:
- Healthy → rep trànsit.
- Unhealthy → no rep trànsit.
Açò permet:
- Aïllar automàticament instàncies amb problemes.
- Mantindre el servei sense interrupcions.
Què és un Health check?
Els health checks són comprovacions periòdiques que fa el Load Balancer:
- Accedix a un port o ruta (per exemple,
/). - Si respon bé → healthy.
- Si falla → unhealthy (queda fora del servei).
Conseqüència important:
- Una EC2 pot estar encesa però no rebre trànsit.
- El sistema continua funcionant amb la resta.
Alta disponibilitat amb Multi-AZ
Per a parlar d’alta disponibilitat real:
- EC2 distribuïdes en AZ diferents.
- Load Balancer associat a subnets de diverses AZ.
Resultat:
- Fallada d’una EC2 → servei actiu.
- Problema en una AZ → servei actiu.
Pràctica
En aquest punt dels continguts, es recomana fer la pràctica 2.
Monitorització amb CloudWatch
CloudWatch és el servei que permet observar què està passant dins del sistema mentre està en funcionament. No corregix errors ni escala recursos automàticament, però proporciona dades objectives que permeten prendre decisions a temps.
En un entorn real, la diferència entre una incidència menor i una caiguda greu sol estar en si el problema s’ha detectat a temps o no.
És important entendre que CloudWatch treballa principalment amb tres conceptes: mètriques, alarmes i dashboards.
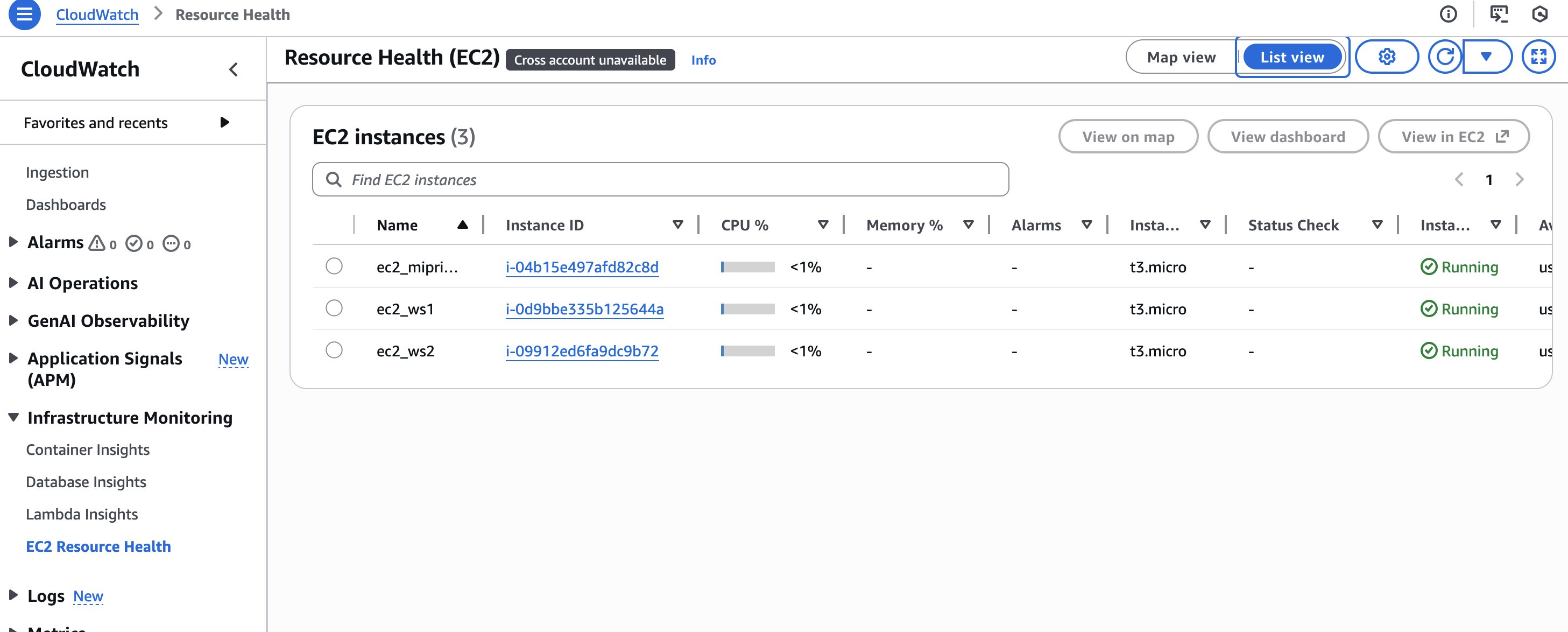
Mètriques
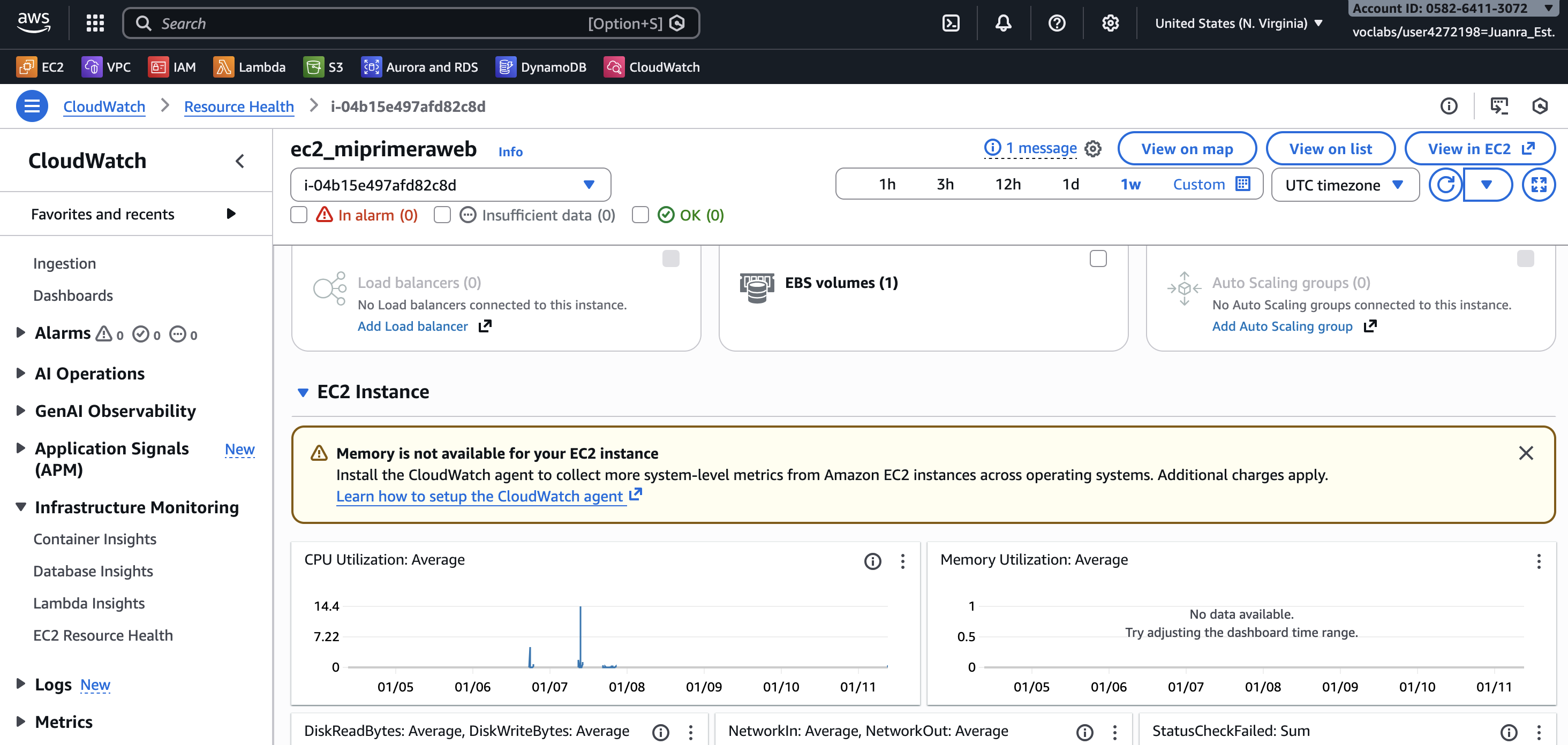
Les mètriques són valors numèrics que AWS recull automàticament dels seus serveis. En el cas de les instàncies EC2, CloudWatch registra dades com l’ús de CPU, el trànsit de xarxa o l’estat general de la instància. Aquestes dades es mostren en forma de gràfics i permeten observar l’evolució del sistema al llarg del temps.
Situació real
En una situació real, frases com “la web va lenta” no són útils si no van acompanyades de dades. Una mètrica de CPU que es manté per damunt del 80 % durant diversos minuts és una evidència clara d’un problema de càrrega, mentre que un pic puntual pot no tindre cap impacte real.
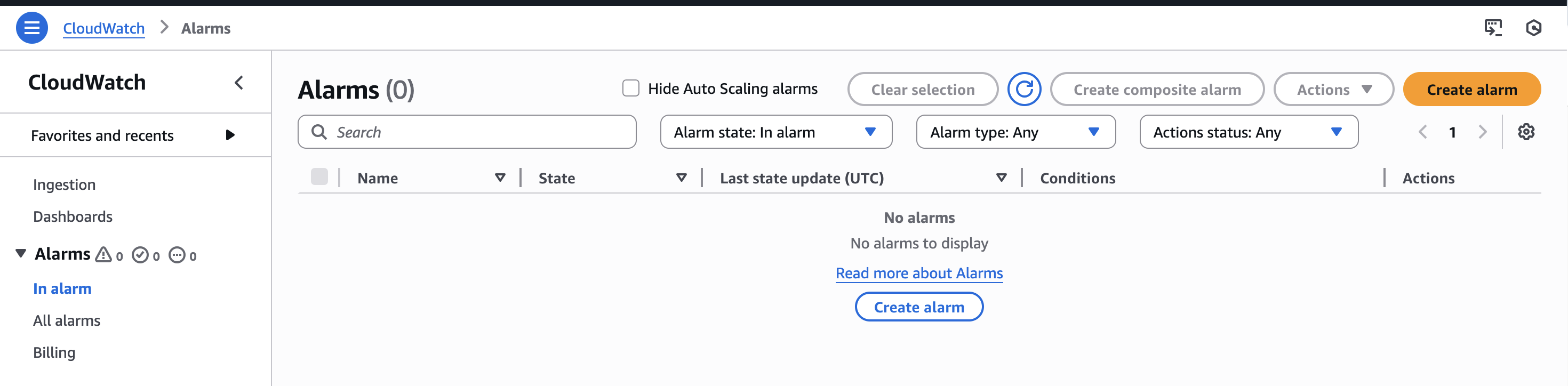
Alarmes
Les alarmes són el següent pas natural després de les mètriques. Una alarma no és més que una condició aplicada a una mètrica concreta. Quan aquesta condició es complix durant un període determinat, l’alarma canvia d’estat i indica que alguna cosa no va bé.
En aquest bloc es treballa amb alarmes senzilles però molt representatives, com ara una alarma que es dispara quan l’ús de CPU d’una instància supera un cert llindar durant diversos minuts. L’objectiu no és configurar moltes alarmes, sinó entendre per què una alarma ben definida pot evitar problemes greus.
En AWS Academy no es treballa amb notificacions avançades, però el simple canvi d’estat de l’alarma (d’OK a ALARM) ja permet visualitzar clarament quan el sistema entra en una situació de risc. En entorns reals, aquest mateix mecanisme s’utilitza per enviar correus, missatges o alertes a equips d’operació.
Estats de les alarmes:
- OK
- ALARM
- INSUFFICIENT_DATA
Dashboards
Els dashboards de CloudWatch permeten agrupar mètriques i alarmes en una sola pantalla. Són, en la pràctica, el quadre de comandament del sistema. Gràcies als dashboards, un administrador pot veure d’un colp d’ull si el sistema està sa, si alguna instància està baix molta càrrega o si el Load Balancer està detectant problemes de salut.
Important
Un bon dashboard no és aquell que té molts gràfics, sinó aquell que mostra només la informació rellevant.
Pràctica
En aquest punt dels continguts, es recomana fer la pràctica 3.
Curs AWS Academy Cloud Foundations
En aquest punt s'ha de realitzar el mòdul 10 (Monitoreo y escalado automático) del curs d' AWS Academy Cloud Foundations.